Python 3.13t makes true threaded parallelism possible, but the real decision is about workload shape, shared state, isolation, dependencies, and scaling limits.
Multithreading in Python
In Python GUI applications, threads have always made sense for keeping the interface responsive. A worker thread can handle long-running work while the main GUI thread continues to process events.
Threads are also useful for I/O-bound tasks such as reading files, downloading data, or waiting for network responses.
CPU-bound work has historically been different. In traditional CPython, the Global Interpreter Lock, or GIL, prevents multiple Python threads from executing Python bytecode in parallel. That means CPU-heavy threaded code often performs no better than single-threaded code, and can even be slower because of scheduling and locking overhead.
Python 3.13 changes the picture. It introduces an experimental free-threaded build, often called no-GIL Python, where Python threads can run concurrently across multiple CPU cores.
Here is why multithreading may become useful for some CPU-bound tasks, and how to evaluate whether Python 3.13t fits your workload.
For I/O-bound workloads, free-threading is usually not the first tool to reach for. asyncio can handle many concurrent network or database operations in a single thread without introducing shared-memory locking concerns. Free-threaded Python mainly changes the discussion for CPU-bound workloads where threads previously could not execute Python bytecode in true parallel.
Why Multithreading May Become Useful
Before Python 3.13, you had to use the multiprocessing module to bypass the GIL for CPU-heavy tasks.
While effective, multiprocessing runs work in separate Python processes, each with its own interpreter state and Python heap. Depending on the operating system, process start method, copy-on-write behaviour, and worker state, this can introduce memory and data-sharing overhead.
This comes with downsides:
- Memory Overhead: Multiprocessing can increase memory usage, especially when workers receive serialized data, mutate inherited pages, or build separate working heaps. On Unix-style fork-based systems, copy-on-write can reduce the initial overhead, so the real cost depends on the OS, process start method, workload, and when data is initialized.
- Expensive Communication: Sending data between processes requires serializing/deserializing it (pickling), which slows things down.
With free-threading, threads share the same process memory space. Be aware however, that even without the GIL, CPU-bound workloads do not automatically scale linearly. With this biggest obstacle out of the way, others still remain. Memory bandwidth, cache contention, synchronization overhead, allocator pressure or combinations of these will most probably become the new bottleneck.
Why Was the GIL Implemented So Strictly?
To understand why the GIL stayed around for over 30 years, you have to look at the landscape of computing in 1991, when Guido van Rossum first created Python.
Back then, multi-core consumer CPUs didn’t exist. Computers had a single processor that did one thing at a time. The GIL wasn’t a lazy design shortcut; on the contrary it was an elegant engineering decision for its time.
It was built rigidly for three massive reasons:
1. Python’s Memory Strategy: Reference Counting
Python tracks when to delete objects from memory using reference counting. Every time you assign an object to a new variable or pass it to a function, its internal counter goes up. When a variable goes out of scope, the counter goes down. If it hits zero, Python frees the memory.
Without a GIL, if two threads tried to increment or decrement the reference count of the same object at the exact same time, a race condition would occur.
- The count could get corrupted.
- An object might get deleted while a thread is still using it (causing a crash).
- Or, it might never get deleted, creating memory leaks.
To fix this without a GIL on a multi-core system, you would have to put a lock around every single reference count update.
2. Guido’s performance requirement (The Single-Thread Penalty)
In the late 1990s and early 2000s, engineers tried to remove the GIL. The most famous attempt was Greg Stein’s “free-threading” patch for Python 1.5.
He successfully removed the GIL by putting fine-grained locks on all reference counts and dictionary lookups. It worked, and it allowed multi-core scaling!
But there was a catch: because locking and unlocking thousands of times a second adds massive overhead, some single-threaded workloads became significantly slower, often cited around 40% in early attempts.
Guido van Rossum famously laid down a rule: “I would welcome a set of patches into the master branch only if the performance for a single-threaded program doesn’t decrease.”
Because 99% of computers at the time were single-core, slowing down everyone’s everyday code by 40% just to make hypothetical multi-core code faster was a terrible trade-off.
3. C Extensions and Ecosystem Success
Python didn’t become popular because it was fast; it became popular because it was an amazing ‘glue’ language. It made it very easy to wrap fast C/C++ libraries (like early database drivers and graphic tools) and call them from Python.
Because the GIL guaranteed that only one Python thread ran at a time, C extension authors had a simpler default model: while holding the GIL, they generally did not need to make every interaction with Python objects thread-safe. Extensions that released the GIL or used their own shared state still needed proper synchronization.
It made writing libraries dead simple. If Python had forced strict thread safety on day one, the massive ecosystem of plugins and libraries we enjoy today might never have caught on.
How to Effectively Use Multithreading in Python 3.13+
Because removing the GIL can break older code that implicitly relied on it for thread safety, Python 3.13 handles this by offering two separate executables. To get true parallelism, you have to actively use the free-threaded version.
Install and Run the Free-Threaded Binary
When you download Python 3.13, you must ensure the free-threaded binaries are installed (it’s an optional checkbox in Windows/macOS installers, or available via packages like python3.13-nogil on Linux).
They named the free-threaded executable explicitly with a t suffix. To run your script with the free-threaded build, use py -3.13t my_script.py instead of py -3.13 my_script.py.
Verify the GIL is Actually Off
You can check using the free-threaded CPython build programmatically in your code using the new sys._is_gil_enabled() function.
# test whether free-threaded mode is enabled
import sys
try:
if not sys._is_gil_enabled():
print("Success! Running in true parallel, free-threaded mode.")
else:
print("The GIL is still enabled.")
except AttributeError:
print("Pre-3.13 Python: The GIL is definitely enabled.")Use ThreadPoolExecutor for CPU Tasks
For suitable CPU-bound workloads, you can now consider ThreadPoolExecutor instead of immediately reaching for ProcessPoolExecutor. Here is a quick example of running some heavy math operations across threads:
# Test ThreadPoolExecutor
from concurrent.futures import ThreadPoolExecutor
import time
def cpu_heavy_task(n):
# A simple CPU-bound countdown
count = 0
for i in range(n):
count += i
return count
def main():
numbers = [20_000_000] * 4
start_time = time.perf_counter()
# Utilizing threads for CPU-bound work
with ThreadPoolExecutor(max_workers=4) as executor:
results = list(executor.map(cpu_heavy_task, numbers))
print(f"Finished in {time.perf_counter() - start_time:.2f} seconds")
if __name__ == "__main__":
main()On my laptop, an Intel(R) Core(TM) i9-14900HX (2.20 GHz) with 32 GB of installed RAM, running this script with 3.13 takes 1.42 seconds, with 3.13t it takes only 0.53 seconds.
Hold on…
That is indeed a huge performance gain but note it has only been measured with this specific task on this particular machine. This minimal sanity check shows that real parallel speedup is possible, not that every CPU-bound workload will scale linearly.
As already noted above. Disabling the GIL removes one major bottleneck, but it does not magically remove all bottlenecks. Depending on the workload, scaling can also be limited by memory bandwidth, CPU cache contention, synchronization, allocator behavior or third-party library behavior.
The right question therefore is not does Python 3.13t make threads fast? We need to be much more specific: would this specific workload benefit from parallel execution inside one process?
For many CPU-bound workloads, especially those involving large numeric buffers, multiprocessing combined with multiprocessing.shared_memory remains an important alternative. It can reduce copying while preserving process isolation, but shared writable memory still requires explicit synchronization.
In standard CPython, threading has historically shined most for I/O-bound work or C extensions that release the GIL. Free-threaded CPython expands the cases where threading may also be useful for CPU-bound Python code, but only when the workload is parallelizable and the dependency stack supports it.
Note: shared memory stays exposed also in multiprocessing. Even with the GIL, compound updates such as x += i should not be treated as safe concurrent updates to shared mutable state.
It consists of multiple operations: read the current value, compute the new value, and store it back. Another thread can interleave between those steps. The GIL constrains execution, but it is not an application-level lock for your program’s invariants.
Thread Safety Still Matters
The GIL protected CPython’s internal interpreter state, especially around object memory management and reference counting. It was not an application-level synchronization mechanism, and Python code could not use it as a proper lock.
Therefore, free-threaded Python does not change the semantics of thread safety. Correctly synchronized code remains correctly synchronized. Racy code remains racy.
What changes is the concurrency profile. In the free-threaded CPython build, Python code has more opportunities to execute truly concurrently across CPU cores. As a result, incorrect assumptions around shared mutable state may become easier to expose in practice.
The practical rule is not new, but it becomes more important to apply consistently: if multiple threads mutate shared state, protect that state deliberately with locks, queues, ownership rules, or immutable data structures.
Python 3.13 introduces a revised, highly optimized native locking mechanism called threading.Lock (powered internally by a new, lightweight PyMutex). Use it whenever threads mutate shared state:
# safely using counter_lock
import threading
shared_counter = 0
counter_lock = threading.Lock()
def safely_increment():
global shared_counter
# Protect modifications to shared data
with counter_lock:
shared_counter += 1A Quick Warning on Ecosystem Compatibility
Free-threaded Python is not only about the interpreter. Your dependencies matter too. If you use third-party C-extension libraries, such as older versions of NumPy, pandas, SciPy, or Cython-based modules, they may not yet be fully compatible with free-threading.
Some extension modules that are not marked as free-threading compatible may cause the GIL to be re-enabled at runtime, reducing or eliminating the expected parallel speedup.
Before expecting true parallel performance, check whether your dependencies officially support free-threaded CPython and test your actual workload.
What Changed in 3.13?
Python core developers and researchers spent years working around this trade-off. Python 3.13’s free-threaded mode relies on a breakthrough technique called Biased Reference Counting (invented by Sam Gross).
It realizes that most objects are only ever touched by the single thread that created them. It uses a super-fast, lock-free counter for the “owning” thread, and only uses expensive atomic locks if a different thread tries to touch the object.
This helped reduce the historical single-thread penalty enough to make an experimental no-GIL build viable.
The GIL vs. No-GIL Benchmark Script
Now that you know the backstory, let’s look at how to benchmark it on your current setup. Here is a script I have designed to stress-test your CPU and highlight the exact performance difference between running with and without the GIL.
This script fires up a heavy, CPU-bound mathematical task (calculating a large number of primes) across multiple threads. It checks your CPU core count and splits the work evenly.
# BENCHMARK
import sys
import time
from concurrent.futures import ThreadPoolExecutor
import os
# 1. Define a heavy CPU-bound task
def is_prime(n):
if n <= 1:
return False
for i in range(2, int(n**0.5) + 1):
if n % i == 0:
return False
return True
def count_primes_in_range(start, end):
count = 0
for i in range(start, end):
if is_prime(i):
count += 1
return count
def run_benchmark():
# Detect available CPU cores
num_cores = os.cpu_count() or 4
print(f"Detected {num_cores} CPU cores.")
# Check GIL status (Python 3.13+)
gil_status = "ENABLED"
try:
if not sys._is_gil_enabled():
gil_status = "DISABLED (Free-threaded mode)"
except AttributeError:
gil_status = "ENABLED (Pre-3.13 Python)"
print(f"Current Python Interpreter GIL Status: {gil_status}\n")
# Scale the workload based on cores
# We will find primes up to 1,000,000 split across chunks
total_range = 1_000_000
chunk_size = total_range // num_cores
tasks = []
for i in range(num_cores):
start = i * chunk_size
end = start + chunk_size
tasks.append((start, end))
print(f"Spawning {num_cores} threads to calculate primes...")
start_time = time.perf_counter()
# Using ThreadPoolExecutor (which is bound by the GIL in standard Python)
with ThreadPoolExecutor(max_workers=num_cores) as executor:
# Submit all chunks to the thread pool
futures = [executor.submit(count_primes_in_range, s, e) for s, e in tasks]
results = [f.result() for f in futures]
end_time = time.perf_counter()
total_primes = sum(results)
elapsed = end_time - start_time
print("-" * 40)
print(f"Found {total_primes,:} primes.")
print(f"Total Execution Time: {elapsed:.4f} seconds")
print("-" * 40)
if __name__ == "__main__":
run_benchmark()The results on my laptop (specs above): Found 78,498 primes. Total Execution Time: 1.4798 seconds with 3.13; with 3.13t this is reduced to only 0.1841 seconds!
Exact numbers will vary by CPU, operating system, Python build, background load, and workload size. The point of the benchmark is not the absolute timing, but the relative difference between standard 3.13 and 3.13t on the same machine.
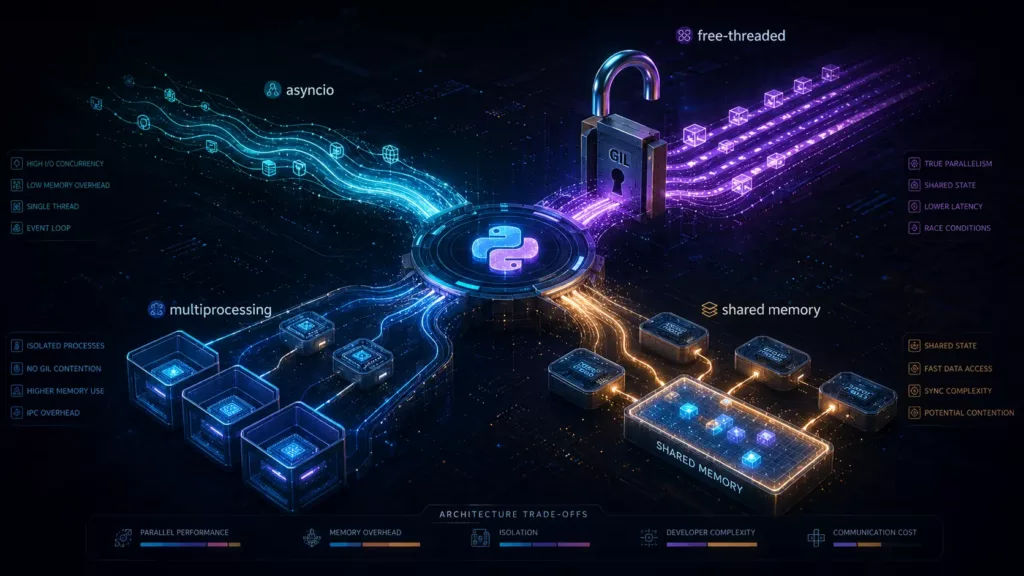
Practical Use
To put this into practical use, the goal is no longer about choosing either multithreading or multiprocessing. In Python 3.13 and beyond, the real superpower is combining them or migrating smoothly between them depending on your hardware and your data.
Here is a pragmatic Decision Matrix on how to design architectures for modern Python.
The decision is not simply “threads versus processes.” A more accurate comparison is between shared-state and isolated-state designs.
Race conditions are not caused by threads alone. We cause them by unsynchronized shared mutable state. Threads make shared memory easy by default. Processes make isolation the default. If processes use shared writable memory, they require the same synchronization discipline.
Free-threaded threads make shared in-process memory easy. Multiprocessing makes isolation the default. multiprocessing.shared_memory sits between those two models: it preserves process isolation while allowing selected data buffers to be shared explicitly.
Matrix
| Capability / Constraint | threading / free-threaded | multiprocessing | multiprocessing + shared_memory |
| Memory Footprint | Very low: threads share the same process memory space | Potentially high; depends on OS, start method, copy-on-write behavior, serialized task payloads, and worker state | Lower than ordinary multiprocessing for large shared arrays/buffers, but each process still has its own interpreter and heap |
| Data Sharing Overhead | Very low: threads can pass references/pointers inside one process | Often high: data usually has to be pickled, serialized, or copied between processes | Lower for large numeric buffers because workers can access shared memory directly; still needs metadata/coordination |
| State Isolation | Low by default: shared memory is easy, but accidental shared mutation is also easier | High by default: processes have separate Python heaps and clearer state boundaries | Medium: process isolation remains, but shared writable memory reintroduces synchronization concerns |
| Race Condition Risk | Exists when multiple threads mutate shared state without synchronization | Lower by default because state is usually not shared directly | Exists when multiple processes mutate shared memory without synchronization |
| Failure Isolation | Low: a process-level crash can take down the whole application | High: a crashed worker process can often be restarted | High for process crashes, but shared-memory corruption or coordination bugs can still affect correctness |
| Serialization / Pickling Cost | Minimal for in-process objects | Often significant | Reduced for shared buffers, but control messages and Python objects may still need serialization |
| Best Fit | CPU-bound workloads that partition cleanly, benefit from shared memory, and use thread-safe code/dependencies | CPU-bound workloads where isolation, robustness, and compatibility matter more than memory-sharing overhead | CPU-bound workloads with large numeric/data buffers where copying would dominate, but process isolation is still useful |
| Ecosystem Safety | Requires free-threading-compatible Python and dependencies | Better compatibility with older libraries and C extensions | Better compatibility than threads in some cases, but shared-memory design must be explicit and careful |
| Max Scale | One machine / one process, limited by physical cores and memory bandwidth | Can scale across processes and, with external systems, across machines/clusters | Usually one machine for shared memory; can be combined with distributed multiprocessing frameworks |
In other words, free-threading is not the only way to avoid copying large data. Its advantage is that shared memory is natural inside one process. The advantage of multiprocessing.shared_memory: sharing is explicit while process isolation is mostly preserved.
Practical Architecture: Hybrid Concurrency
For complex, large-scale applications, the best approach is often a Hybrid Architecture: Use multiprocessing to distribute chunks of work across separate machines or completely isolated worker nodes, and use free-threaded threading inside each process to maximize core utilization without ballooning your RAM usage.
Code Example
Imagine you are building a data processing pipeline that loads a 10GB dataset into memory, performs heavy CPU math, and writes results to a database (IO tasks).
Here is how you write a clean, modern pipeline using concurrent.futures. This script dynamically adapts, utilizing threads for the heavy lifting while bypassing serialization bottlenecks.
Using the free-threaded interpreter, ThreadPoolExecutor can now replace rocessPoolExecutor for some CPU-bound workloads, especially when shared memory and low serialization overhead matter. ProcessPoolExecutor is still valuable for crash isolation, compatibility, and distributed architectures.
# hybrid multi-threading, multi-processing
import os
import time
from concurrent.futures import ThreadPoolExecutor
# Simulated CPU-bound heavy mathematical operation
def heavy_math_transform(data_chunk):
result = []
for item in data_chunk:
# Simulate CPU work
val = sum(i * i for i in range(item))
result.append(val)
return result
# Simulated IO-bound operation (e.g., writing to a database or disk)
def save_to_storage(result_data):
# Simulating network/disk latency
time.sleep(0.1)
return f"Saved {len(result_data)} rows successfully."
def process_pipeline(large_dataset):
cores = os.cpu_count() or 4
print(f"Executing pipeline utilizing {cores} cores via Free-Threading...")
# Step 1: Split data into chunks for our threads
chunk_size = len(large_dataset) // cores
chunks = [large_dataset[i:i + chunk_size] for i in range(0, len(large_dataset), chunk_size)]
start_time = time.perf_counter()
# Step 2: CPU-BOUND PHASE (Leveraging Free-Threading)
# In Python 3.13t, this can scale across cores without duplicating memory,
# assuming the workload and dependencies are compatible.
with ThreadPoolExecutor(max_workers=cores) as cpu_executor:
print("-> Starting CPU-bound transformations...")
transformed_chunks = list(cpu_executor.map(heavy_math_transform, chunks))
# Flatten results
flat_results = [item for chunk in transformed_chunks for item in chunk]
# Step 3: IO-BOUND PHASE (Leveraging standard async/thread pooling)
with ThreadPoolExecutor(max_workers=2) as io_executor:
print("-> Starting IO-bound storage saving...")
# Split saving into two concurrent tasks
half = len(flat_results) // 2
io_futures = [
io_executor.submit(save_to_storage, flat_results[:half]),
io_executor.submit(save_to_storage, flat_results[half:])
]
for future in io_futures:
print(f" {future.result()}")
print(f"Pipeline finished in {time.perf_counter() - start_time:.4f} seconds.")
if __name__ == "__main__":
# Generate a mock dataset of 4,000 integers requiring heavy computation
mock_dataset = [5000] * 4000
process_pipeline(mock_dataset)Production Checklists for 3.13+
Free-threaded CPython in 3.13 is still experimental, so treat it as a promising architecture option rather than a universal drop-in replacement for multiprocessing.
If you are migrating from multiprocessing to free-threading:
- Audit shared mutable state. Multiprocessing often avoids shared-state bugs by default because each process has its own Python heap unless memory is explicitly shared. Threads share a process memory space, so mutable objects accessed by multiple threads need clear synchronization, ownership, or immutability rules.
- Check C-extension compatibility. If your code relies on NumPy, pandas, SciPy, Cython modules, or other compiled extensions, verify that they support free-threaded CPython.
- Benchmark your real workload. Synthetic benchmarks are useful, but the real result depends on memory access patterns, lock contention, dependency behavior, and CPU architecture.
- Keep multiprocessing where isolation matters. If crash protection, process isolation, or distributed execution is important, multiprocessing remains the better architectural choice.
When to stick purely to Multiprocessing:
- The “Crash Protection” Requirement: If a thread triggers a process-level crash (e.g., a critical Segmentation Fault from a C-library), it kills the entire Python application. If a subprocess crashes, the main process lives on and can restart it. If stability/isolation is your top priority, stick to multiprocessing.
- Distributed Computing: Threads cannot leave the physical machine. If you need to scale across AWS EC2 instances or Kubernetes nodes, you must use multiprocessing networks (like Celery, Ray, or PySpark).
Conclusion
Free-threaded Python does not make concurrency magically simple. It shifts the trade-off. You gain true parallel execution inside one process, but you also inherit more responsibility for thread safety and dependency compatibility.
For CPU-heavy applications that process large shared datasets, Python 3.13t is one of the most important changes to CPython in years. In Python 3.14, the free-threaded build is no longer experimental, although it remains optional rather than the default interpreter. Used carefully, it can simplify architectures that previously required multiprocessing, shared memory, or external worker systems.
Python 3.13t removes one major historical blocker for CPU-bound threading, but the real architectural decision (still) depends on state sharing, isolation, dependency support, serialization costs, and scaling limits.
Update
An earlier version of this article could be read as implying that the GIL made Python application code thread-safe. That was not the intended point. The GIL protected CPython’s internal interpreter state and constrained true parallel execution, but it was never an application-level synchronization mechanism. Free-threading does not redefine thread-safety semantics: correctly synchronized code remains correct, and racy code remains racy. What changes is the concurrency profile. With true parallel execution, latent race conditions around shared mutable state may become easier to expose in practice.
A new post on LinkedIn summarizes this article.